Abstract
Object counting is a challenging task with broad application prospects in security surveillance, traffic management, and disease diagnosis. Existing object counting methods face a tri-fold challenge: achieving superior performance, maintaining high generalizability, and minimizing annotation costs.
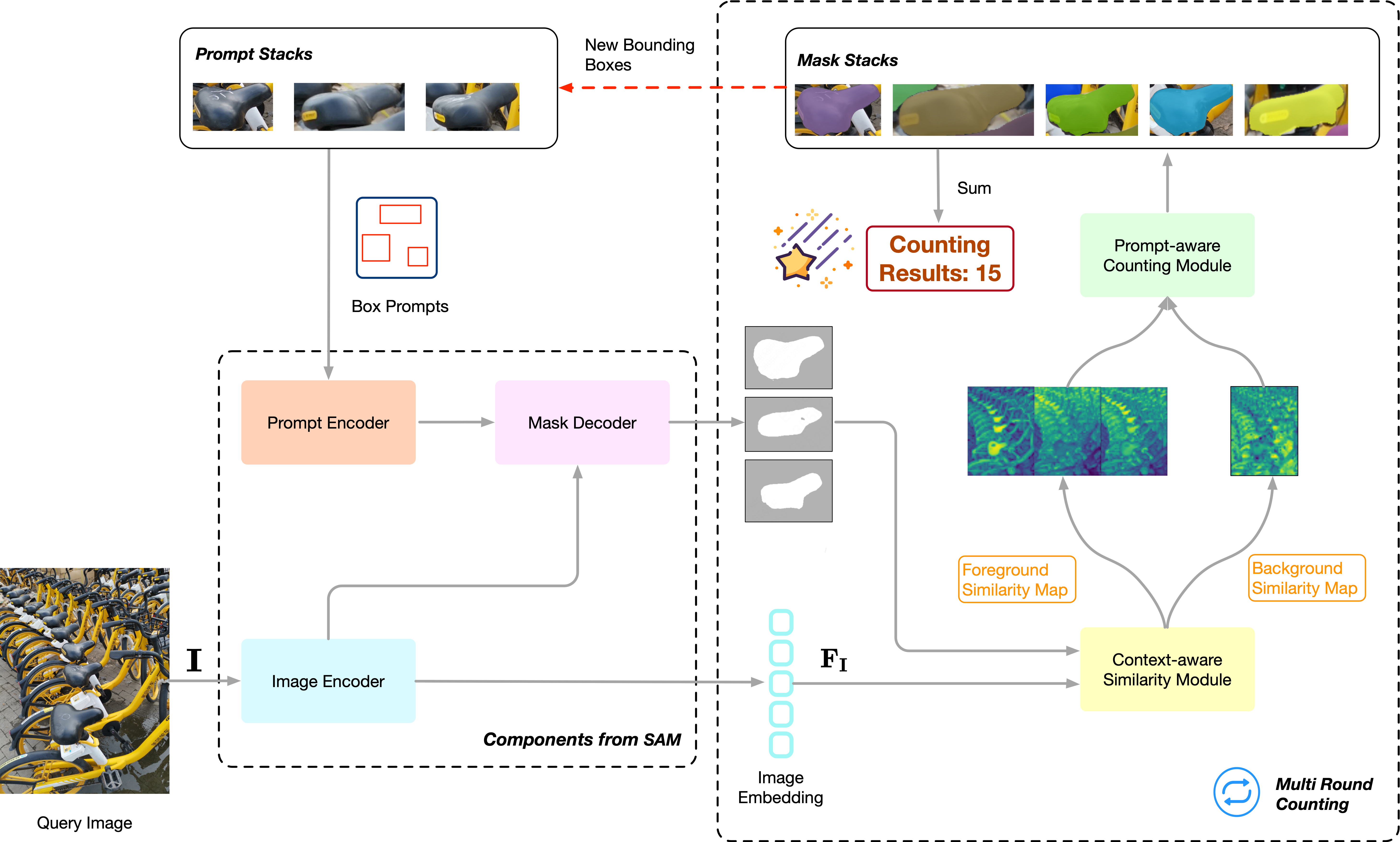
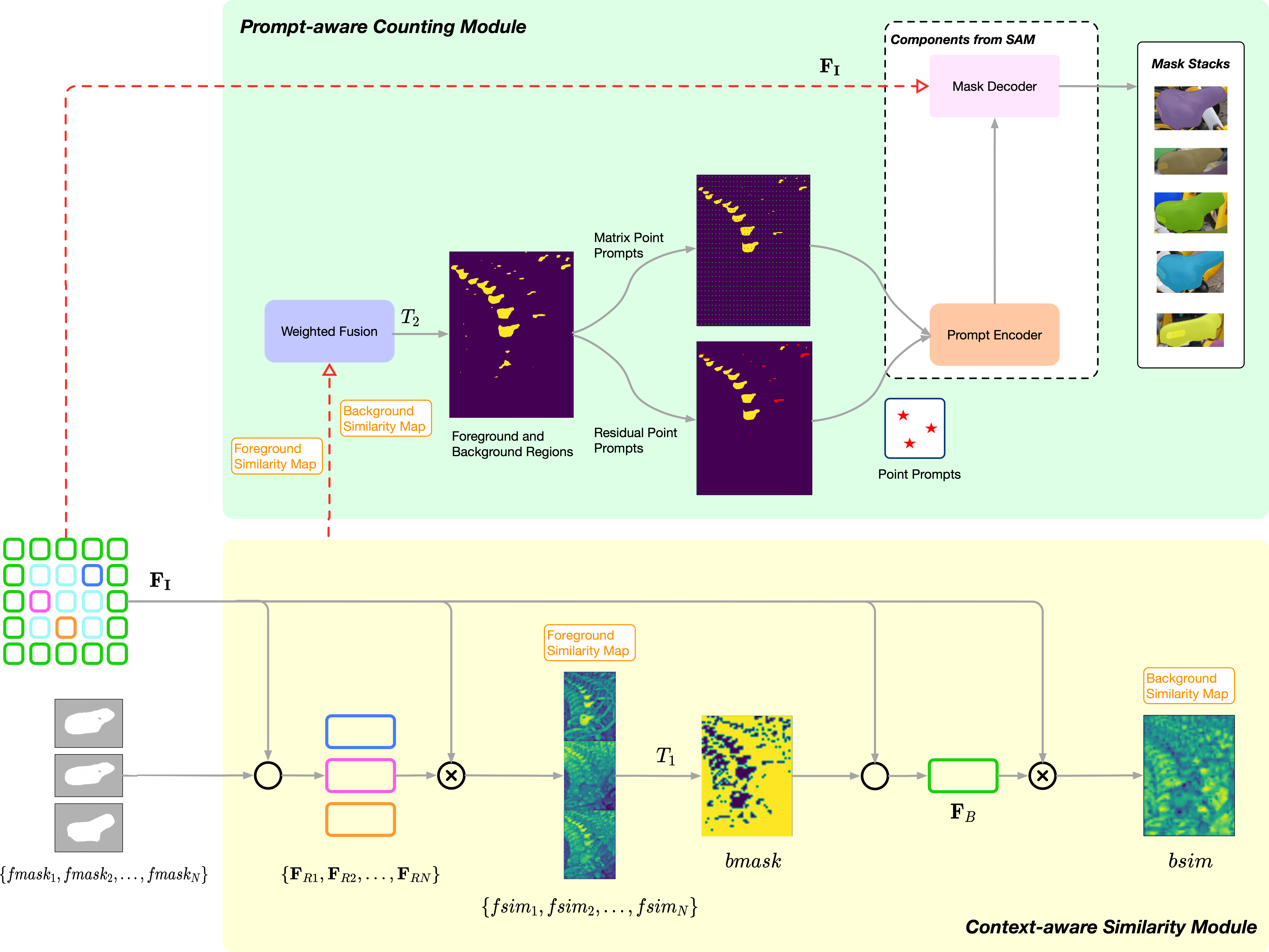
We develop a novel training-free class-agnostic object counter, TFCounter, which is prompt-context-aware via the cascade of the essential elements in large-scale foundation models. This approach employs an iterative counting framework with a dual prompt system to recognize a broader spectrum of objects varying in shape, appearance, and size. Besides, it introduces an innovative context-aware similarity module incorporating background context to enhance accuracy within messy scenes.
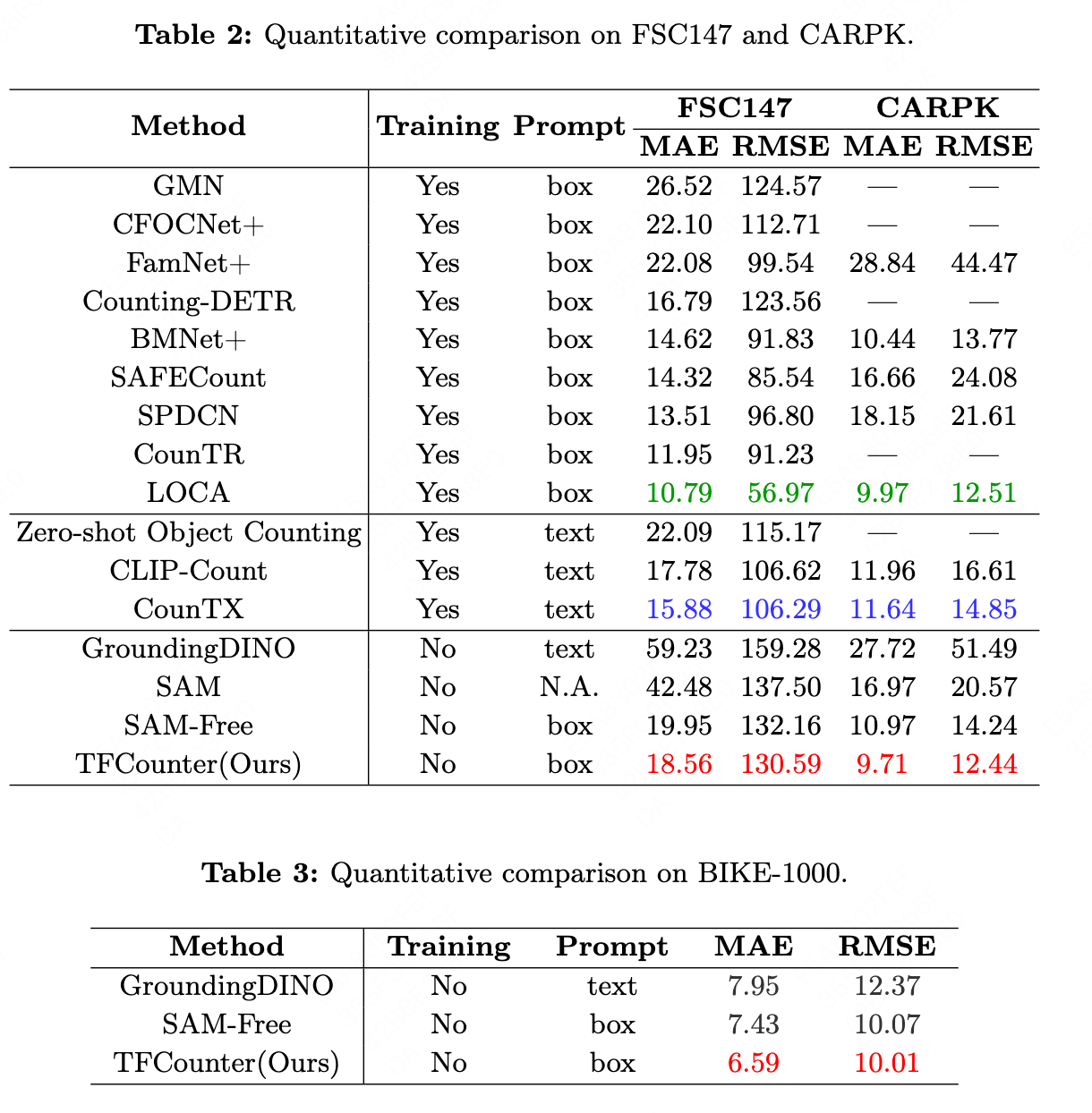
To demonstrate cross-domain generalizability, we collect a novel counting dataset named BIKE-1000, including exclusive 1000 images of shared bicycles from Meituan. Extensive experiments on FSC-147, CARPK, and BIKE-1000 datasets demonstrate that TFCounter outperforms existing leading training-free methods and exhibits competitive results compared to trained counterparts.